Create Q&A from Essays and Twitter Threads, using Open AI Embedding and Pinecone

I am always eager to experiment with new technology and share my experiences and insights gained through trial and error. Currently working as Backend Engineer.
After some time of researching Open AI, Vector databases, and semantic search. For today, I tried to combine all of the knowledge I get and create Q&A based and search for 400 Twitter threads and essays of Illimitablemen IM
Luckily, I found this Paul Graham GPT on GitHub. This is basically what I want to build. Tweak some here and there. 60% of the work is already done.
What I need to do now is gather all the data, create the vector, insert it into Pinecone, then queried it.
For better understading, please go to the series: https://dev.fandyaditya.com/series/openai-semantic-search.
Any step that seems missing will be found on that series.
Scrapping the data
For the threads. Because I don't have access to the twitter APIs. I need to find another way.
Rattibha one of Threadsaver-bot, give me access to IM's 400++ threads. Which means, many twitter user use Rattibha to save IM's twitter-thread.
For the essay, I can got it from his blog illimitablemen.com
Maybe because of the structure or I just suck at selecting HTML elements and using any HTML parser, it takes a long time for me to scrape and clean the data. I create a script for it, but I also use Chrome extension web scraper tools to collect some of the data. Manually cleaning it if the script or the tools not cleaning it well. I scrape the text content, link of the source tweet/essay, and the created date of the content and store it into JSON.
Create embedding and store it
After data is gathered, now we create the embeddings. Before we embed, we chunk the data first. I use Langchain to do that.
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 0 });
const fileJson = //where the data stored
const splittedText = await textSplitter.splitText(fileJSon.text);
RecursiveCharacterTextSplitter is a Langchain module that makes chunking text very easy. I choose 1000 chunk size, which means I want the chunk consists of max 1000 characters each.
Now we need to create embedding and store the data to Pinecone. But before we do that, we need to specify the content of the metadata that we want to query later. For this project, we just need the text content, the title, and the link so we can navigate it to the source essay/tweet.
I use Langchain Pinecone Vector Store module to do this. We also need to convert the chunk into Document object.
import { PineconeStore } from "langchain/vectorstores";
import { OpenAIEmbeddings } from "langchain/embeddings";
let documents = [];
splittedText.forEach((txt) => {
const document = new Document({
pageContent: txt,
metadata: {
title: fileJSon.title,
createdAt: fileJSon.createdAt,
link: fileJSon.link.url
}
});
documents.push(document);
});
PineconeStore.fromDocuments(documents, new OpenAIEmbeddings(), { pineconeIndex: pinecone.index('indexname'), namespace: 'namespacename' })
With PineconeStore.fromDocuments function, the chunks are automatically turned into embedding and inserted into the pinecone index.
Take note: document.pageContent will be converted into metadata.text in vector in pinecone db. This is important for querying later.
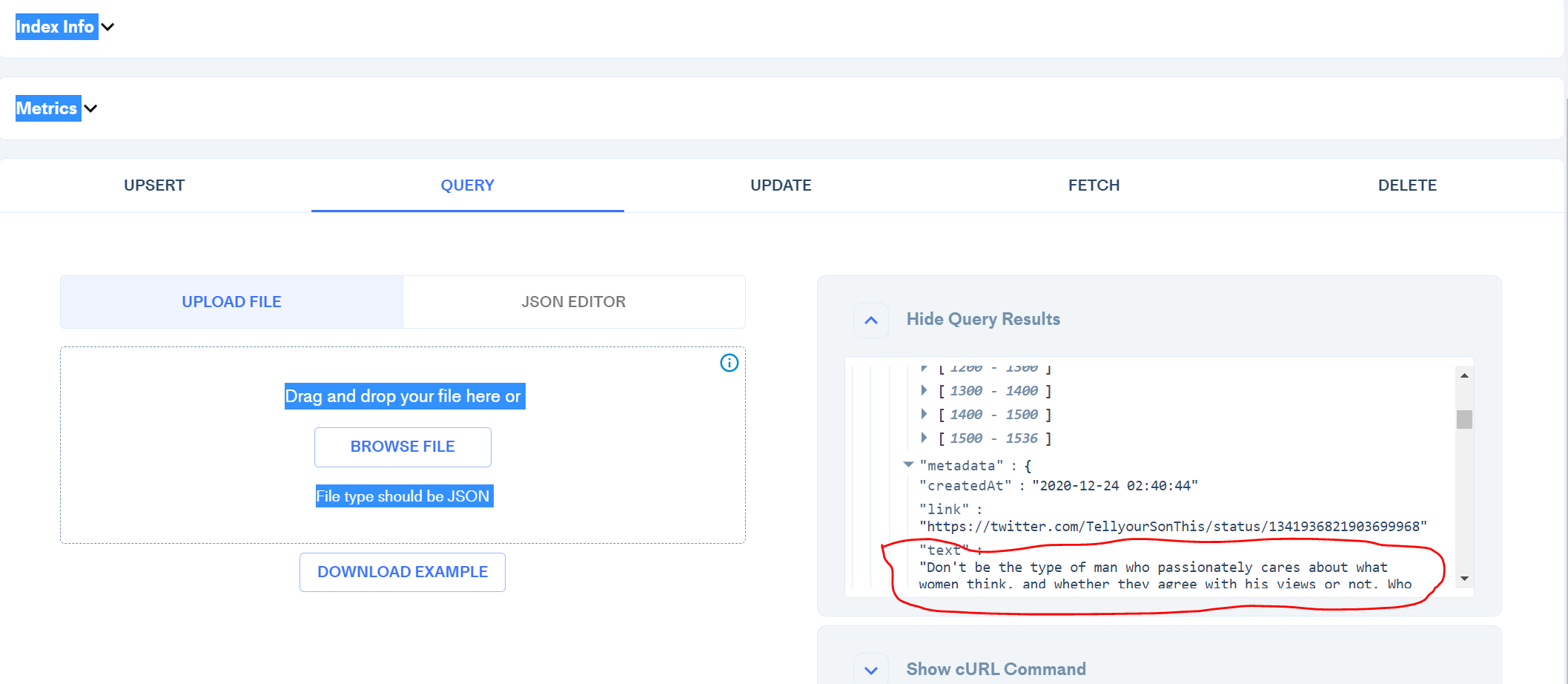
Now the data is stored and ready to use!
Create the Q&A Apps
As i mention before, I built this on top of this repo. Need a little tweak. Because it use supabase, i need to change it into pinecone.
//pinecone.js
export const query = async (embed) => {
await pinecone.init({
environment: process.env.PINECONE_ENVIRONMENT,
apiKey: process.env.PINECONE_API_KEY
});
const index = pinecone.Index('indexname');
const queryRequest = {
vector: embed,
topK: 5,
includeValues: false,
includeMetadata: true,
namespace: 'namespacename'
}
try {
const response = await index.query({ queryRequest })
const mappedResponse = response.matches.map((item) => {
return {
metadata: item.metadata
}
})
return { data: mappedResponse }
}catch(err) {
return { error: err }
}
}
Then change for any code that calls Supabase query into this function.
And done!
Try it here: https://illimitablemen-gpt.vercel.app/.
Special Thanks
Thanks to IM for the awesome writing. Very eye-opening, make me become a better person. I highly recommend to follow him and read his essays.
And also mckaywrigle for Open Sourced Paul Graham GPT.




