
F
I am always eager to experiment with new technology and share my experiences and insights gained through trial and error. Currently working as Backend Engineer.
Search for a command to run...
I am always eager to experiment with new technology and share my experiences and insights gained through trial and error. Currently working as Backend Engineer.
No comments yet. Be the first to comment.
Integration between Hashnode and Canva that you'd never expect

Introduction Generated AI is one of the latest tech. The progress is swift, and it actually helpful for many jobs in every aspect of people's lives. The most groundbreaking tech discovery after spreadsheet :p. Everyone uses it. LLM like ChatGpt, trai...

I have been using Notion for my personal blog. Start with using premium paid service Super.so when it still in the early bird. Super is great, it just works, that's what I want, but when it gets popular I don't have the luxury to pay 12$ per month fo...

Over the past three years, I have been working on aggregator apps. These apps essentially act as intermediaries between users and various systems. The main goal is to provide a seamless user experience by allowing them to interact with multiple syste...

For the past few months, I have already had in mind, what if we can ask a video. Instead of watching for hours, we can ask about only certain topics that we are interested in. We are in the podcast era. There are tons of 3-hour-long videos and of course, it needs dedicated time to watch the full episode. So, asking about the content of the video, and going deeper on the topic that we truly want to know is an efficient way to gain knowledge or information. With Hackaton by MindsDB, this is the chance to actually build something cool. So here it is: YoutubeAsk. Telegram Bot to ask any YouTube video.
I've been following MindsDB since the last hackathon on April 2023. But, when at that time, I underestimated the true challenge of the hackathon. The true challenge is to finish. Because every time I see, hundreds or thousands that registered, only few that submit. So, I didn't want to miss it again, this hackathon is a chance to actually build and ship.
What I expect from this hackathon is two things. Building the idea that I already have in mind, and exploring & contributing to the hottest topic of the year: Generative AI, and the tools that support to make it easy and possible.
MindsDB is an open source, AI Engine, that makes it easy to build AI tools. With hundreds of databases, and apps integration ready to use using SQL - Like Syntax and HTTP Rest APIs. In today's era, where AI is the hottest topic you can't miss MindsDB. Making AI Tools is easy because you can leave the heavy work to MindsDB. Also, the team and communities are so active in adding new integrations every day.
The experience is new. This is my first time exploring deeply an open source and actually understand what I read haha. Finding something that is not documented, finding a gem, a new way to do something that actually possible by only reading the code and trial-error so we can get. This is really new experience.
And of course, MindsDB makes the heavy part of building the YoutubeAsk easy. Almost 70% of the work is done with the MindsDB feature and integration. What I did was glue it all together and build things. The possibilities are endless. Like, you can create thousands of combinations of apps and functionalities, only with MindsDB. Pretty cool!
My flow when working on this project is like this:
Read the documentation on the web.
If not find what I want, go to the source code, to the integration handler module
Read README on the integration handler
If not satisfied, read the unit test
If not available, directly read the handler code.
The deeper I find, the higher the satisfaction of finding something. Like finding a hidden gem.
MinsdDB is the core of YoutubeAsk. But there are some other tools needed.
Express JS
This project uses Express JS as a simple web server.
Telegram bot
Why Telegram Bot?
I use Telegram,
I think Telegram has good bot APIs
Create a Telegram Bot first. What we need is:
Register via Bot Father
Save the bot token
Follow this tutorial on how to register a telegram bot.
Ngrok
For development, we need to register webhook to telegram bot APIs, so telegram knows, where it "forwards" the chat message. We can get what chat data is sent to the bot, and process it in our server.
In the local machine, we need some kind of tunneling. After a little research, I found this tool: Ngrok.
With ngrok, we can create a secure tunnel from my local laptop to the internet. With this, I can register my local development server as the webhook to the telegram bot.
Follow the instructions here
MindsDB will be the core of the apps that we want to make. MindsDB currently can create a Knowledge Base. It's like (Correct Me If I'm wrong Lol) AI storage that can answer any Natural Language query based on the knowledge that is inserted to them. So this is the core of the YoutubeAsk. We need a Knowledge Base based on video YouTube content that asked/registered. Next, where i can get the YouTube data to give feed to the Knowledge Base? Magically, Mindsdb is already have the integrations!
MindsDB have YouTube API Integrations that already can get comments, video info, and channel info based on the id given. For YoutubeAsk, what I want to get is video info, to feed the knowledgebase. Gladly MindDB already has it. So convenient!
Oh, also you need a YouTube API key. Follow this tutorial
Vector Databases is the core of Knowledge Base. Because every data inserted, is inserted as vector, and queried as matching vector to understand the queries and find the related content. This process called Semantic Search. Knowledge Base wrap this into APIs that easy to use. So we just like query to some SQL databases. There's some vector databases that can be integrated to MindDB. I choose the familiar one: ChromaDB.
OpenAI Integration is used in model on this project. Go to OpenAI to get one.
I'm quite familiar with docker. So when there are Docker images of MindsDB, I just use it on my local machine. But the original images do not come with the dependency of YouTube and Chromadb integration, so I need to do a little tweak. Creating custom Dockerfile, with MindsDB images as bases and adding extra dependencies:
# Use the mindsdb/mindsdb base image
FROM mindsdb/mindsdb
# install mindsdb youtube plugin
RUN pip install mindsdb[youtube]
# install mindsdb chromadb plugin
RUN pip install mindsdb[chromadb]
# RUN pip install pysqlite3-binary
# This create folder is needed for chromadb integration can run
RUN mkdir -p /usr/local/lib/python3.10/site-packages/google/colab
# Set the entry point with the installation and MindsDB command
ENTRYPOINT ["sh", "-c", "python -m mindsdb --config=/root/mindsdb_config.json --api=http,mysql,mongodb"]
Yes, installing YouTube and ChromaDB Mindsdb integration plugin. There some mkdir process, that will explained on the next section.
To build the images, run:
# Build docker
docker build -t my_mindsdb .
Run the images
docker run -p 47334:47334 -p 47335:47335 my_mindsdb
Go to browser and access localhost:47734, it will take some time after docker container successfully runs. You will see Mindsdb Admin UI.
For more info on docker installation, go here.
Next, we go to the development.
I want to make it pretty basic and simple, yet deliver. So the bot becomes like this:
/ask [youtube-link]: to set the video that you want to ask
/session: to check the current video
After ready then start asking like regular chat. Simple.
With the help of MindsDB, building something like this is pretty straightforward. Here is the flow.
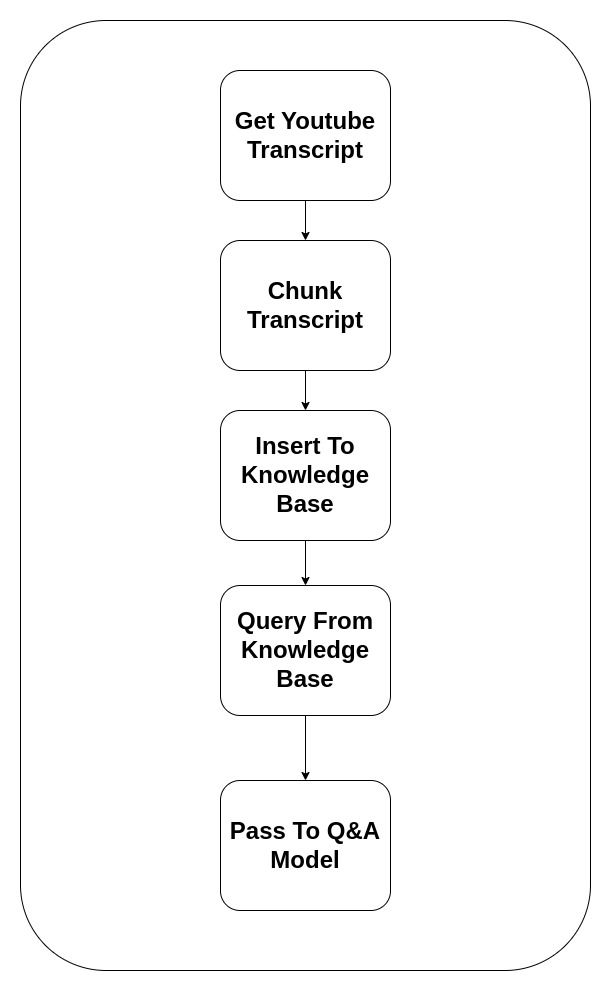
Let's dive into it
Get Youtube Transcript
First, we need to initialize YouTube integration.
CREATE DATABASE youtubedb
WITH ENGINE = 'youtube',
PARAMETERS = {
"youtube_api_token": "AIzxxx" -- your youtube api token
};
Then to get the video transcript, like this:
SELECT transcript FROM youtubedb.videos WHERE video_id = '${id}'
Done! We get the transcript. The data are like this:
[
{
"text": "This is some transcript"
"start": 1.0,
"duration": 3.6,
},
{
"text": "This is another transcript"
"start": 4.7,
"duration": 3.9,
},
...
]
Chunk the transcript
We need to chunk the transcript so we can search it. Because it is already on a JSON array, I chunk it based on 10 items. Every item is an average of 5 seconds clip. So if we chunk every 10 items, we get ~50 seconds of clip for each chunk.
Insert to Knowledge Base
Before we can insert into it, we need some preparation. Create the ML Engine, Model, and Knowledge Base:
--Setup ml engine
CREATE ML_ENGINE embedding FROM langchain_embedding;
CREATE ML_ENGINE openai_engine
FROM openai
USING
api_key = 'sk-xxxx'; -- your openai api key
--Create embedding model
CREATE MODEL openai_embedding_model
PREDICT embeddings
USING
engine = "embedding",
class = "openai",
api_key = "sk-xxxx", -- your openai api key
input_columns = ["content"];
-- Create qna model using openai
CREATE MODEL q_n_a_model
PREDICT answer
USING
engine = 'openai_engine',
prompt_template = 'Use the following pieces of video context to answer the question at the end. If you do not know the answer, just say that you do not know, do not try to make up an answer. Dont answer outside of the context given.
Video context: {{context}}
Question: {{question}}
Helpful Answer:',
model_name= 'gpt-3.5-turbo-16k',
mode = 'default',
max_tokens = 1500;
-- Connect to Chroma
CREATE DATABASE chromadb
WITH ENGINE = "chromadb",
PARAMETERS = {
"persist_directory": "chromadb/"
};
-- create youtube_ask table, we need to spesify init dummy data so chromadb collection can be created
CREATE TABLE chromadb.youtube_ask (
select content, '{"data": "init data"}' as metadata, embeddings
from openai_embedding_model
where content = 'init content'
);
--Create knowledge base
CREATE KNOWLEDGE_BASE youtube_ask_kb
USING
model = openai_embedding_model,
storage = chromadb.youtube_ask;
I followed Knowledge Base and Q&A documentation for preparing The Knowledge Base, and Q&A model, with a little tweak:
Changing Embedding Model using OpenAI
Add parameter model_name of Q&A Model to gpt-3.5-turbo-16k, max_tokens to 1500 and mode to default . Changing model name to that, so we can send 16k token context to the OpenAI. Max token to 1500 so the response is not truncated. And it can all work, when I use mode=default.
Now we can insert to the knowledge base using:
INSERT INTO youtube_ask_kb (content, metadata)
VALUES ('chunked content', '{"link": "http://you.tube/link"}')
With content is the chunked content, and the metadata.link is the YouTube video URL. We need the link so we can query the context based on the video given.
Query the knowledge base
Querying knowledge base is pretty straightforward:
SELECT content
FROM youtube_ask_kb
WHERE content = 'Question from user'
AND youtube_ask_kb.metadata.link = 'http://you.tube/link'
Give the queried result to q_n_a_model
Now with data that we get from Knowledge Base, we want to feed LLM so it can give a natural response to the users. Based on the question, and context from the knowledge base data.
SELECT answer
FROM q_n_a_model
WHERE context = 'Data from queried knowledge base'
AND question = 'Question from user'
We will get something like this:
Q: What kind of technique the video suggest to mapping out my week?
A: The video suggests the technique of writing down every single thing you are going to do for the next week. This includes your morning routine, focused work routine, other tasks and meetings, and nightly routine. By writing everything down, you can reduce the friction of making better decisions and spot problems in your days. The video also mentions the importance of experimenting and iterating on your plan week after week to refine your system.
Nice!
I can guarantee that when building things, there are some something that didn't go as planned. For this project, here they are.
Something happened on ChromaDB Installation. After some research, I found the issue. The default Sqlite from Python 3.10 is not compatible with the ChromaDB. So it needs to be installed separately.
I found this post, and scrolling to the comment, and solved it like this:
#Dockerfile
# This create folder is needed for chromadb integration can run
RUN mkdir -p /usr/local/lib/python3.10/site-packages/google/colab
By creating an empty Google Collab folder via Dockerfile, it downloaded separate Sqlite that is needed by the ChromaDB.
The problem with Knowledge Base is when we query something general like: What is the video about? it can't get any data because it doesn't get any matching criteria for that kind of question. So, my fix is, just send all of the transcript to Q&A Model and, let it consume all of the content of the video, and answer based on that.
The second problem occurs. When we use the default configuration for the Q&A Model, it only supports 4k context windows, because it uses text-davinci OpenAI model. When we just send all of the transcript to the model, it error because pass over 4k context. We need to change the model. Because it isn't documented anywhere, I need to dive into the code to find if this is possible or not. Of course, it is possible, and changing to a model gpt-3.5-turbo-16k makes it work. Handling 20~ pages of context is possible now.
Participating in this hackathon gave me new experience and knowledge. Hackaton gives a sense of urgency, with a driving incentive that gives me kind of motivation to explore new things, and actually build an idea that has been urged to be checked on my idea notes. Exploring new tools to create something awesome. Building something becomes easier and easier nowadays. The same applies to MindsDB, creating AI Apps so much easier and faster.
Oh, and also contributing to open source. This is my first time creating PR for Open Source.
Update Documentation of YouTube Integration
Update Documentation of OpenAI Integration
Well, maybe that's not much hahaha. But it's ok, extra documentation may save hours for others.
Thank you to MindsDB and Hashnode for the amazing hackathon. Can't wait for the next hackathon and bringing the next idea a life!
You can find GitHub repo here
Also thank you for reading! Have a nice day!