Semantic Search using OpenAI Embedding and Postgres Vector DB in NodeJS

F
I am always eager to experiment with new technology and share my experiences and insights gained through trial and error. Currently working as Backend Engineer.
Search for a command to run...
I am always eager to experiment with new technology and share my experiences and insights gained through trial and error. Currently working as Backend Engineer.
Great post, congratulations! I'm stuck on error 400 in the last step: node server.js ("'input' is a required property", 'invalid_request_error'). Any support?
Hey, I think that error from openAI Create embedding response. Maybe they detected no input from the apps Are you already add value to the q params?
Fandy Aditya Wirana Hi, you are right, I just needed the input (i.e. the q param), but did not expect to break the code trying to access localhost:9000. Thanks for your reply.
You're welcome!
In this series, I will share what I explore with the new AI Wave: Open AI API and use it to build the semantic search of articles, podcasts, youtube video
For the previous article, we use Postgres with pgvector extension to store the vector data of our article. Today let's try to change the Postgres with Pinecone Vector DB. Previous Article: https://dev.fandyaditya.com/semantic-search-using-openai-emb...
Integration between Hashnode and Canva that you'd never expect

Powered by MindsDB 🤖

Introduction Generated AI is one of the latest tech. The progress is swift, and it actually helpful for many jobs in every aspect of people's lives. The most groundbreaking tech discovery after spreadsheet :p. Everyone uses it. LLM like ChatGpt, trai...

I have been using Notion for my personal blog. Start with using premium paid service Super.so when it still in the early bird. Super is great, it just works, that's what I want, but when it gets popular I don't have the luxury to pay 12$ per month fo...

Over the past three years, I have been working on aggregator apps. These apps essentially act as intermediaries between users and various systems. The main goal is to provide a seamless user experience by allowing them to interact with multiple syste...

This project is about implementing semantic search using OpenAI embedding and Postgres vector database in NodeJS. Semantic search is a search technique that uses natural language processing to understand the meaning of the query and returns results that are semantically related to the query. OpenAI embedding is an API that will convert text into a numerical vector representation that can be used for semantic search. Combining it with the Postgres vector database we can use this to make a semantic search of any text or article we want.
For the example text, I choose https://jamesclear.com/why-facts-dont-change-minds for the article.
Here is the diagram for the API that we want to create. It is split into two functions.

Search the queried text

For the Postgres database, we will be using Supabase. Supabase has a free tier, and we can create and use it instantly.
Let's install the extension for Postgres, open the Supabase SQL editor, and run:
create extension pgvector;
Notes: If this extension needs another extension to install, install that also.
For this project, we use some of the node-js libraries:
"@supabase/supabase-js" // supabase node-js client
"dotenv"// to read .env file
"express" // we use express for rest api framework
"gpt-3-encoder" // we need this for chunk the text
"openai" // openai node-js client
npm install @supabase/supabase-js dotenv express gpt-3-encoder openai
For the environment variable, we need these 3 for this project:
SUPABASE_PROJECT_URL=
SUPABASE_SECRET_KEY=
OPENAI_API_KEY=
Get SUPABASE_PROJECT_URL and SUPABASE_SECRET_KEY (service_role secret) from creating a database from Supabase first, and go to API Settings.
The OPENAI_API_KEY you can get it here.
Our Project structure will look like this:
node_modules
.env
article.txt
embed.js
openAi.js
package.json
server.js
supabase.js
article.txt is the content of the article that we want to search for. So make sure to copy the content of the article there first.
Let's create and store the article chunk's embedding first:
We need to get the text from the article.txt
Before that, let's import the necessary library first.


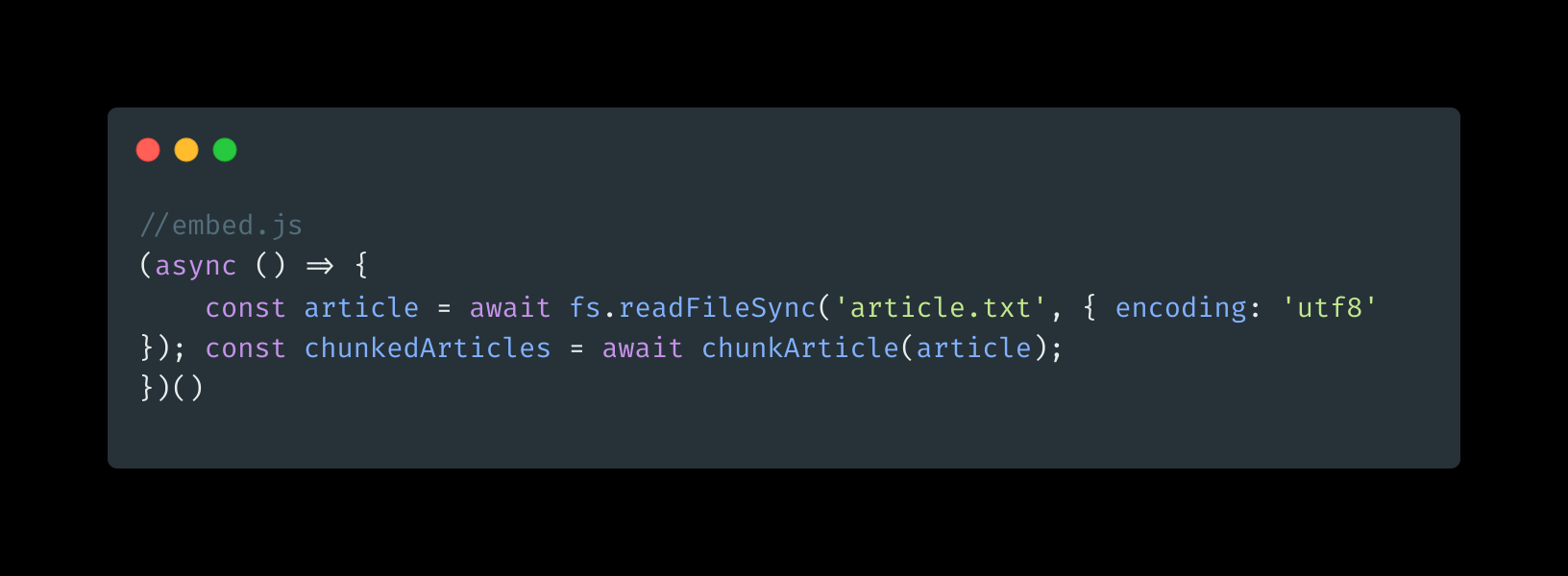
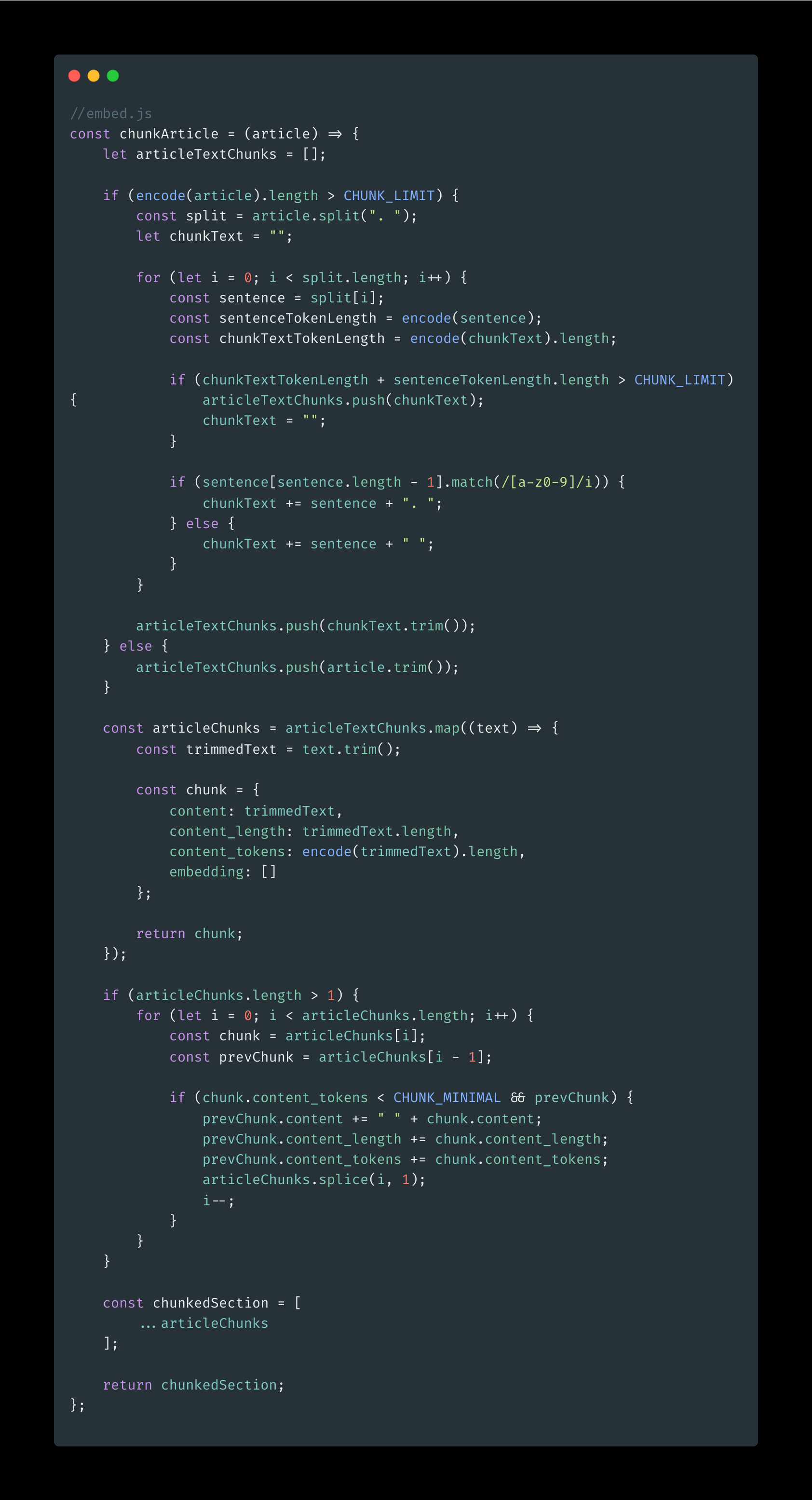
OpenAI has a token system. 1 token means +- 1 word. What we want now is we chunk the article, and split it into limited CHUNK_LIMIT (200 tokens) each. We chunk it, so we can search for it later.
The function first checks if the length of the encoded article is greater than the CHUNK_LIMIT. If so, it splits the article into individual sentences and then concatenates them into chunks that are less than or equal to the CHUNK_LIMIT. It also ensures that a sentence is not split across different chunks by checking if the last character of a sentence is alphanumeric.
Each chunk is represented as an object with four properties: content (the text content of the chunk), content_length (the length of the text content), content_tokens (the number of tokens in the content), and embedding. embedding will be added later.
If the resulting chunks are smaller than the CHUNK_MINIMAL (100 Tokens ), they are merged with the previous chunk. Finally, the function returns an array of the resulting chunks.
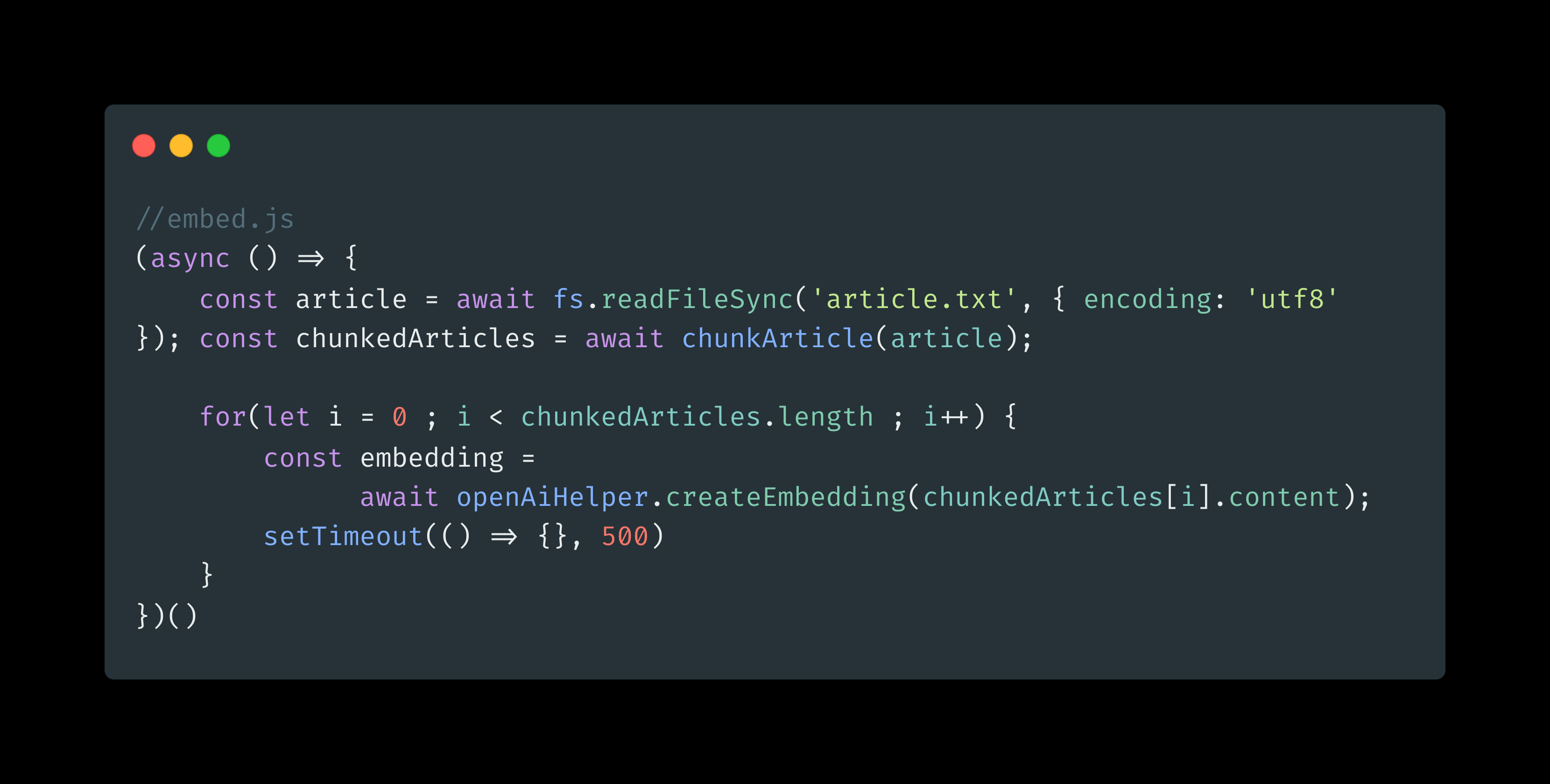
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openAi = new OpenAIApi(configuration);
const createEmbedding = async (input) => {
const embeddingRes = await openAi.createEmbedding({
model: 'text-embedding-ada-002',
input: input
});
const [{embedding}] = embeddingRes.data.data;
return embedding
}
module.exports = {
createEmbedding
}
We need OpenAI's API Create Embedding to create the embedding of the chunked text.
Before we store them, let's create the table first via the Supabase SQL editor:
create table semantic_search_poc (
id bigserial primary key,
content text,
content_tokens bigint,
embedding vector (1536)
);
You can name it whatever you want. I named it semantic_search_poc so our query will be like this:
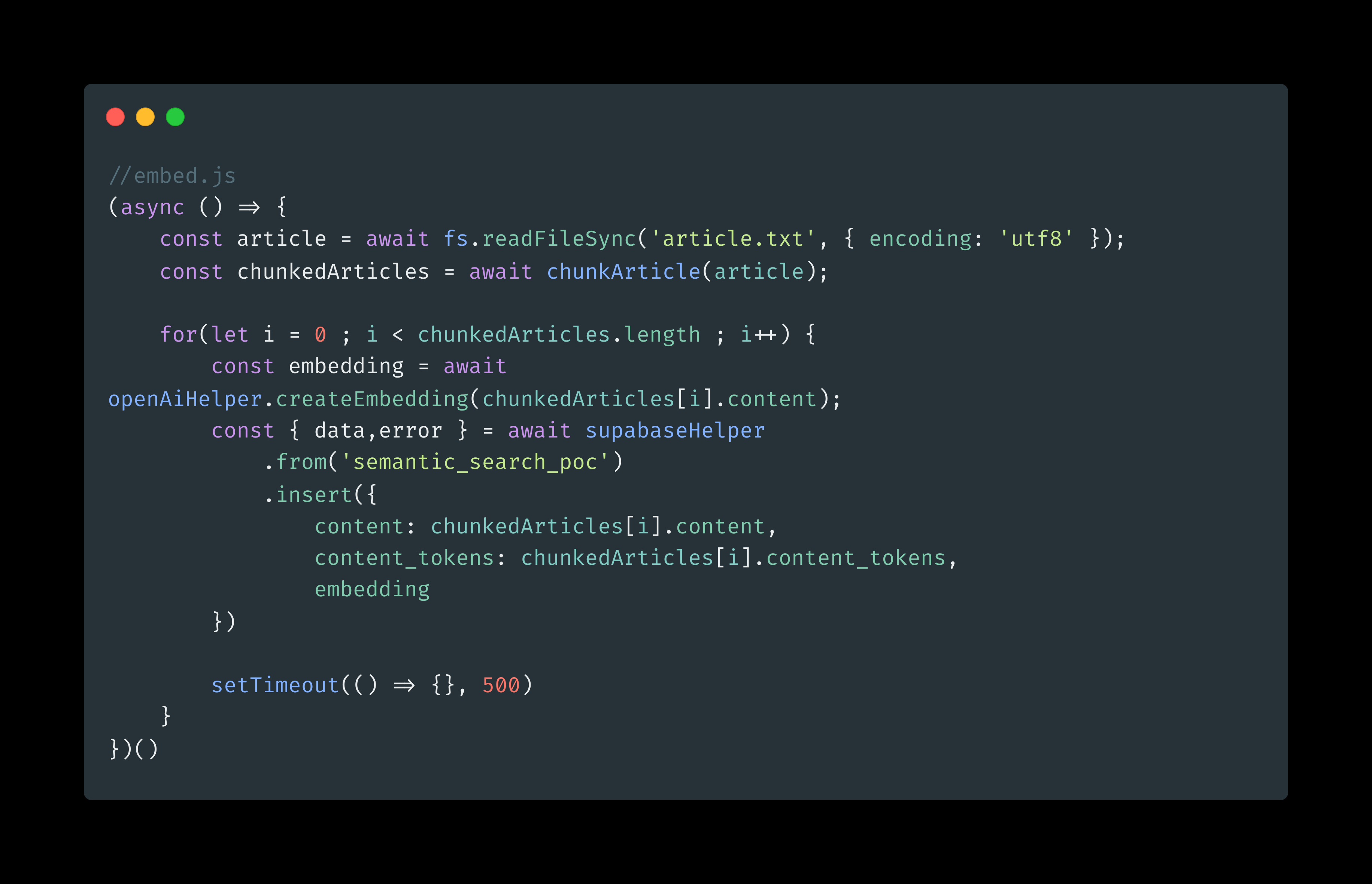

Now run the script
node embed.js
If the process is going smoothly, we will able to see the data in the Supabase table view, something like this:
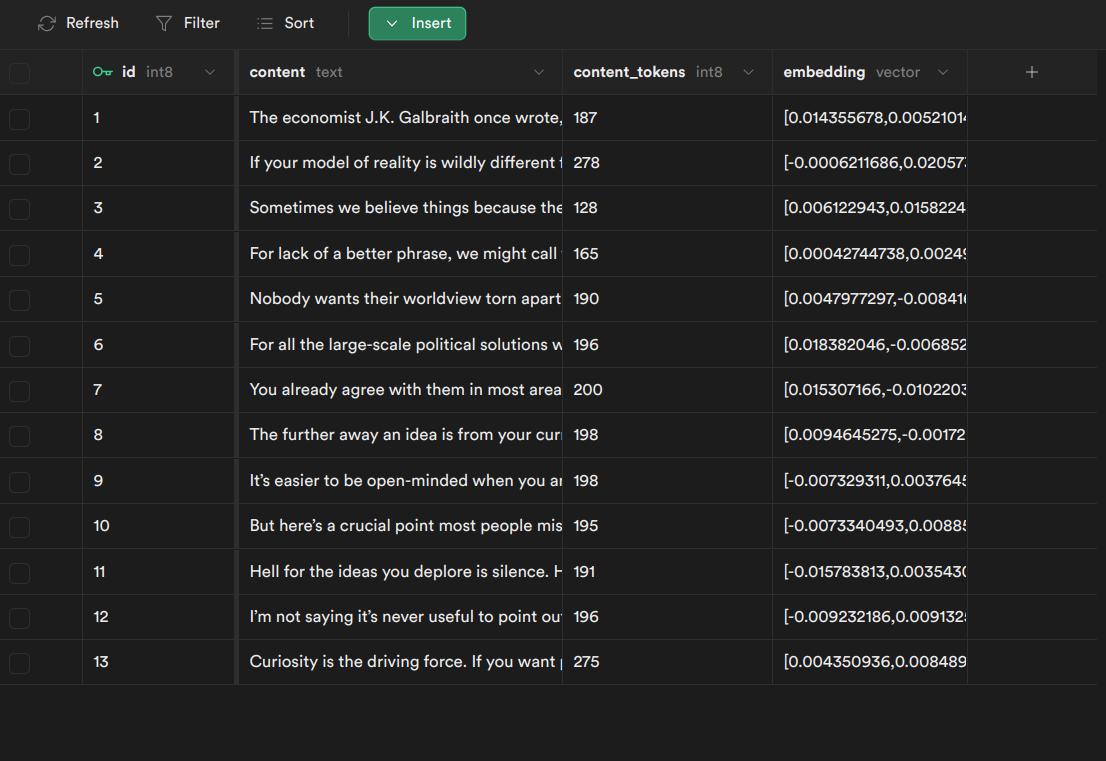
Done! You have success to build the most crucial part of this project!
Now to the next step, queried the data.
We use Express JS to create Rest API Server to get the query from the user. Create simple Express js server code:
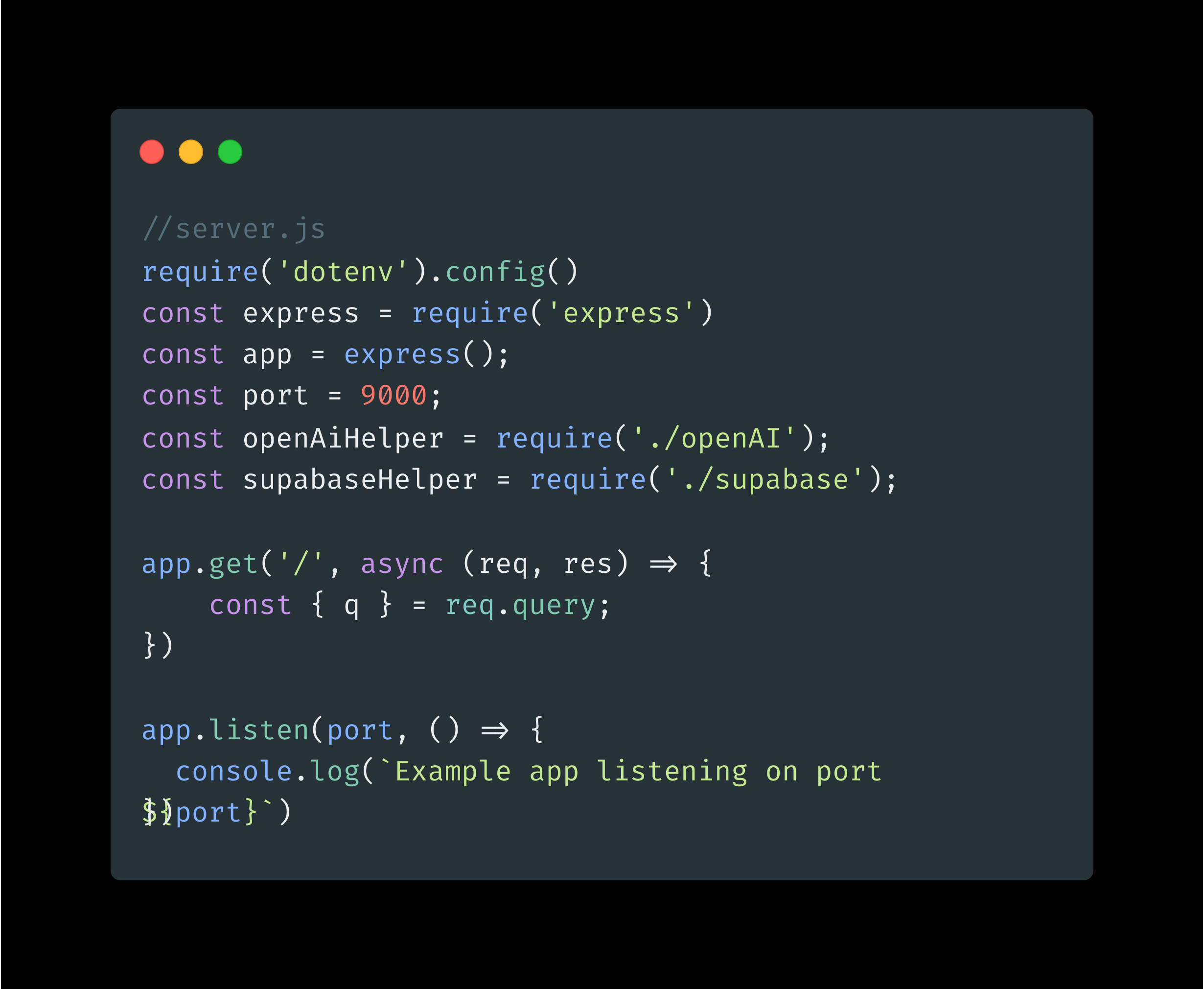
//server.js
app.get('/', async (req, res) => {
const { q } = req.query;
const embedding = await openAiHelper.createEmbedding(q);
})
We use the Postgres function for this search function. So let's head out to the Supabase function editor.
create or replace function semantic_search (
query_embedding vector(1536),
similiarity_threshold float,
match_count int
)
returns table (
id bigint,
content text,
content_tokens bigint,
similiarity float
)
language plpgsql
as $$
begin
return query
select
semantic_search_poc.id,
semantic_search_poc.content,
semantic_search_poc.content_tokens,
1 - (semantic_search_poc.embedding <=> query_embedding) as similiarity
from semantic_search_poc
where 1 - (semantic_search_poc.embedding <=> query_embedding) > similiarity_threshold
order by semantic_search_poc.embedding <=> query_embedding
limit match_count;
end;
$$;
We create a Postgres script that creates a function called "semantic_search". The function takes in a query embedding, similarity threshold, and match count as inputs and returns a table with columns for ID, content, content tokens, and similarity.
The function uses the "semantic_search_poc" table to find rows where the similarity between the query embedding and the content embedding is greater than the similarity threshold. It then orders the results by similarity and limits the output to the specified match count.
The Postgres function is done, now call it on the code
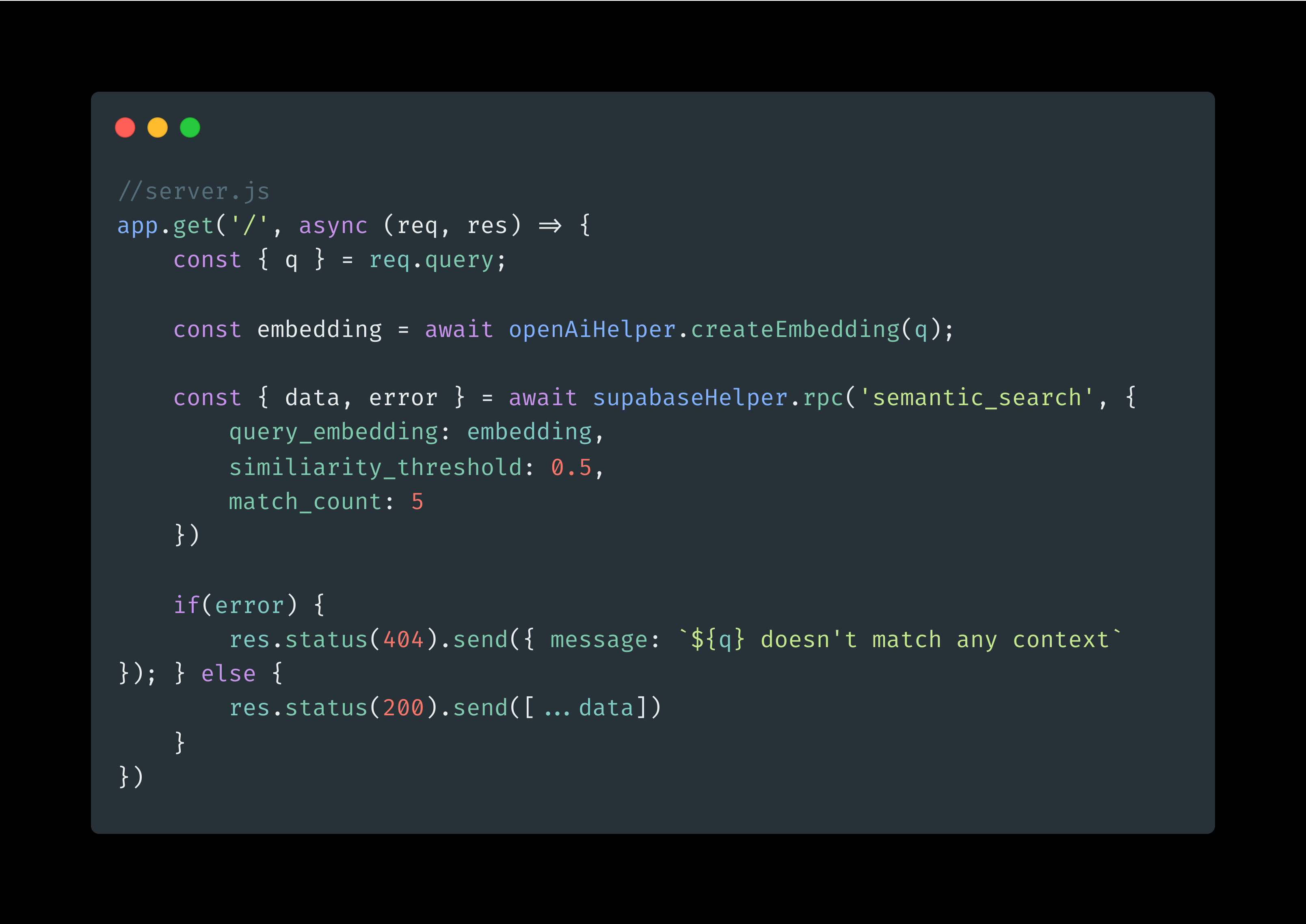
Run the server:
node server.js
Now try to hit GET / with q params something that you want to ask.
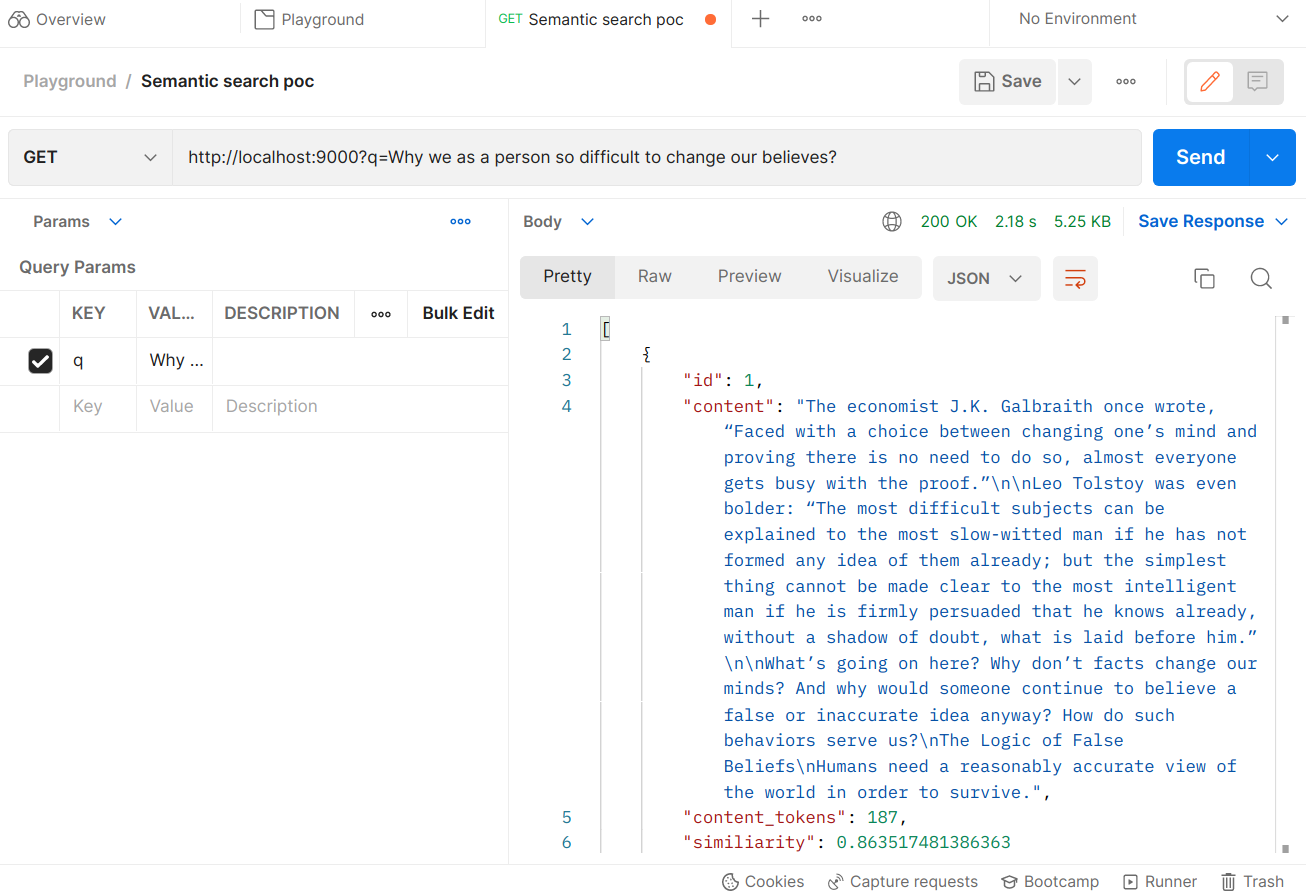
Voila! The API returns the related content ordered by the most similar one.
I hope this article helps to understand how we can create semantic-search apps easily today.
GitHub for this project: https://github.com/fandyaditya/semantic-search-poc
References: https://github.com/mckaywrigley/paul-graham-gpt